Evaluating Agentic Systems with a Testing Pyramid
10-02-2026
I don’t think Agentic AI systems need an introduction anymore. It’s the buzzword right now. But from a QA perspective, it’s a completely different game. So far, we’ve been testing deterministic systems. Given an input and a state, we knew what output to expect. That predictability aspect of the system helped us to write automated tests for traditional software systems.
With agentic systems, that assumption breaks. The same input and state won’t always produce the same output. The system reasons. It makes decisions. It chooses paths. Suddenly, the simple assertions we’ve relied on for years don’t make much sense. We can’t just check for exact matches anymore. We need a different mindset, one that is equally intelligent as the system we are testing.
In theory, we can still shape our test strategy like a pyramid, just as we did for deterministic systems. But the layers in this new pyramid must reflect the probabilistic nature of agentic systems. And more importantly, those layers no longer represent the volume of tests. They represent a logical separation of concerns that is different categories of validation we need in order to build confidence in agentic AI systems.
Test Pyramid for Agentic System
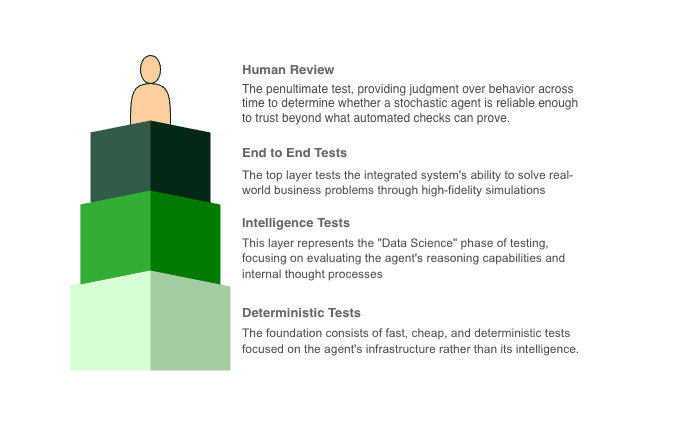
Base Layer (Deterministic Testing)
The base layer of the pyramid represents deterministic testing. This layer is similar to unit testing in conventional software systems, but it is not limited to unit tests alone. It includes tests for all components where AI is not involved and the expected outcome is deterministic.
For Example, JSON schema validation, database clients, API clients, and any other component whose behavior can be verified through fixed inputs and outputs. These components should be tested exhaustively at this layer. This layers sets the foundation of testing, and should be built using simple assertions and reproducible conditions. Depending on the system, it may span unit, integration, functional, and contract tests.
Middle Layer (Intelligence Testing/Trajectories Testing)
In the middle layer of the agentic testing pyramid, we stop asking "Did it return the right output?" and start asking "Did it behave intelligently?" This layer focuses on systems that reason, plan, and act across multiple steps. Because decisions are made through probabilistic models, we evaluate patterns of behavior not fixed outputs. Instead of evaluating a single response, we evaluate the agent’s trajectory: the sequence of thoughts, tool calls, and intermediate decisions it makes from start to finish.
How an Agent Works (Reasoning → Planning → Execution)
On a high level, an agent operates in three stages: Reasoning, Planning and Execution. First, it interprets the goal and context, forming hypotheses about what needs to be done. Next, it creates a structured plan by breaking the goal into ordered steps. Finally, it executes the plan by selecting and calling the appropriate tools with right payload.
What we evaluate at each stage
| Stage | Rubric | What it Evaluates |
|---|---|---|
| Reasoning | Reasoning Coherence | Does the agent's thought process logically follow from the previous observation? Are the "Thoughts" factually grounded in the retrieved context? Did the agent acknowledge and self-correct errors from previous steps? |
| Reasoning | Result Sensitivity | Did the agent correctly interpret the output of the tool? If a tool returned an error (e.g., "user not found"), did the agent's next thought reflect this, or did it hallucinate success? |
| Planning | Plan Adherence | Did the agent actually execute the steps it claimed it would in its plan? Did the agent deviate from the plan without a valid reason (e.g., new information requiring a pivot)? |
| Execution | Tool Selection Accuracy | Given the specific sub-task, did the agent choose the most appropriate tool from its inventory? Did it avoid using a tool when internal knowledge would have sufficed? |
| Execution | Argument Correctness | Were the arguments passed to the tool syntactically valid (e.g., JSON format)? Were the values semantically correct (e.g., extracting the correct dates/IDs from the context)? |
| Execution | Efficiency | Was this step Helpful, Neutral, or Harmful? Did the agent enter a loop (repeating the same tool call with the same args)? Did the agent take a circuitous route (e.g., 10 steps to do a 3-step task)? |
How we evaluate
Golden Sequence Matching
This approach is used to compare the sequence of tool calls made by the agent with a predefined perfect sequence of tool calls. As an outcome of this step, we score the agent based on the similarity between the two sequences.
LLM-as-Judge
This approach is used to evaluate the quality of the agent's responses by using another LLM as a judge. The another LLM which acted as a judge here, has been feeded with golden trajectories to score the trajectories taken by the agent.
A few tool suggestions for evaluating the trajectories.
| Tools | Best for |
|---|---|
| DeepEval | To evaluate tool calling abilities of an agent. |
| Promptfoo | Another tool for evaluating agentic systems. |
| TruLens | An end to end platform for evaluating agentic systems. |
| LangSmith | Allows you to run automated evaluators (LLM judges) over stored traces. You can define a custom judge that reads the trace and scores it on specific criteria like "correctness" or "logic" |
Top Layer (End-to-End Testing)
The top layer of the pyramid represents end-to-end testing of the agentic system. While the lower layers focus on building confidence in individual components and behaviors, this layer is concerned with verifying the system’s ability to solve real business problems as a whole.
At this level, evaluation is scenario-driven rather than component-driven. The objective is not to validate how the agent reasons or which tools it invokes, but whether it can reliably achieve an intended outcome under realistic conditions.
A simple mental model to frame these evaluations:
-
Can the agent do X?
-
Can it do X under Y conditions?
-
Can it do X under Y conditions with Z constraints?
-
How does it behave when given adversarial inputs?
-
How does it respond to inputs that are outside its stated capabilities?
These tests are typically expensive to run, difficult to reproduce, and provide lower diagnostic signal compared to tests in lower layers. For that reason, they should be used sparingly and primarily to validate system-level reliability rather than to debug specific failures.
Human Review
Human review plays a critical role in evaluating agentic systems, particularly at the higher layers of the testing pyramid. Its primary purpose is to judge the judges—to validate whether automated metrics, heuristics, and LLM-based evaluators are producing meaningful and reliable signals.
They observe the observability dashboard, logs, traces to spot the failures and its reasoning. This includes determining whether the agent’s behavior aligned with the intended design, whether constraints were respected, and whether the outcome reflects a genuine system failure or an acceptable tradeoff.
Another area which is mostly overlooked as a part of human review is the evaluation of the agent's performance on the basis of cost and latency.
Human review is also essential for identifying new failure modes that are not yet captured by existing tests or evaluators.
Real-world problems
The synthetic environment problem
Most test environments are built around clean data, valid state, and cooperative behaviour. Real-world usage looks nothing like this. Agents often receive inputs that are noisy, incomplete, ambiguous, or straight up contradictory.
A flight booking agent, for example, may get a request with unclear dates, missing passenger details, or tickets bought under restrictive fare rules (non-refundable, non-changeable, expired offers). In these cases, the agent is forced to reason with missing context, outdated information, and business constraints that were never explicitly provided.
This is hard to simulate in a traditional test setup, but it is exactly where the real evaluation should be happening.
Considering the nature of agentic systems, they are inherently capable of writing data, making API calls, and interacting with the real world. Evaluation should therefore not stop at happy-path testing. A much higher emphasis must be placed on understanding the damage an agent can cause when it behaves unexpectedly, misinterprets intent, or operates outside its intended boundaries.
Mocks
Mocking is another area where agentic testing diverges from conventional testing.
In the traditional testing world, we replace dependencies with clean, predictable mocks. In reality, real-world APIs are that friendly. They time out, return error responses, or may behave weirdly under load.
Testing agents against perfectly behaved mocks hides important failure modes. For agentic systems, mocks should reflect real-world conditions as much as possible.
When feasible, using real APIs in sandboxed environments with fake users often gives far better signal than static mocks.
Over-reliance on LLM-as-a-judge
It is hard to fully trust a non-deterministic system being evaluated by another non-deterministic system. Yet, LLM-as-a-judge has become a common and often necessary approach.
The problem starts when we over-index on the scores. High scores can easily create a false sense of confidence. A good score does not mean the agent is reliable. More often, it means the test cases, inputs, or evaluation criteria are not interesting enough.
This is not new. In conventional testing, automated tests mostly protect us from failures we already understand. The most damaging issues are usually the ones we never thought to test for.
The cost factor
Cost is often ignored early on, but it becomes a serious concern over the time.
Running LLM-as-a-judge evaluations, generating synthetic data, and operating agentic systems in production all come with a significant price tag. These costs compound quickly as systems scale.
Evaluation strategies need to be designed with longevity in mind. The frequency of running llm-as-a-judge evaluations should be carefully considered. Otherwise, teams end up with test suites that are technically sound but economically unsustainable.
Security concerns
There is no shortage of content discussing security risks in agentic systems, especially prompt injection. Despite all the research and mitigation attempts, prompt injection remains a fundamental and largely unsolved problem.
Testing for prompt injection is particularly difficult. The input space is effectively infinite, and natural language does not lend itself to exhaustive coverage. As a result, security evaluation for agentic systems is never “done” — it is continuous and reactive by nature.
Melt Down problem
In sandbox environments, agentic systems are usually evaluated with limited memory and short-lived sessions of hours. In the real world, users often keep sessions active for days or even weeks. In such scenarios, agents are expected to retain and reason over long histories of conversation, tool calls, and system state to perform tasks correctly.
In long-running simulations, agents have been observed to drift or spiral into incoherent behavior. Over time, they struggle to preserve context, lose track of prior decisions, and misinterpret the present state, even when individual steps appear correct in isolation.